直接使用MapReduce 处理大数据,将面临以下的问题:
- MapReduce 开发难度大,学习成本高
- Hdfs 文件没有字段名,没有数据类型,不方便进行数据的有效管理
- 使用MapReduce 框架开发,项目周期长,成本高
Hive 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表(类似于RDBMS中的表),并提供类SQL查询功能,HIVE是Facebook开源,用于解决海量结构化日志的数据统计。
- hive 的本质是:将SQL转化为MapReduce的任务进行运算。
- 底层有HDFS来提供数据存储
- Hive 可以理解成为将SQL转化为MapReduce 任务的工具。
数据仓库是一个面向主题,集成的,相对稳定的,反映历史变化的数据集合,主要用于管理决策,数据仓库本身不产生数据,存储了大量数据。
Hive 和 RDBMS对比
由于Hive 采用了类似SQL的查询语言HQL(hive query language),因此很容易将Hvie理解为数据库。其实从结构上来看,Hive 和 传统的关系数据库除了拥有类似的查询语言,再无类似之处。
- 由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL,数据SQL开发的开发者可以很方便的数据Hive进行开发。
- 由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;而RDBMS可以支持的数据规模比较小。
- Hive 中大多数查询的执行是通过Hadoop提供的MapReduce来实现的,而RDBMS通常有自己的执行引擎。
- Hive的数据都是存储在HDFS中的,而RDBMS是将数据保存在本地系统或裸设备中。
- Hive存储的数据量大,在查询数据的时候,通常没有索引,需要扫描整个表,加之Hive使用MapReduce作为执行引擎,这些因素都会导致较高的延迟,而RDBMS对数据的访问通常是基于索引的,延迟比较滴,当然这个低是有条件的,即数据规模比较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出并行的优势。
- 可拓展性。Hive支持水平扩展;通常RDBMS支持垂直拓展,对水平拓展不太友好
- 数据更新。Hive对数据更新不友好;RDBMS支持频繁,快速数据更新。
Hive 的优缺点
Hive 的优点
- 学习成本低:提供了类SQL查询语言HQL,可以快速上手
- 海量数据分析: 基于MapReduce提供海量计算的功能。
- 系统可以水平拓展,底层基于Hadoop;
- 功能可以拓展,Hive允许用户自定义函数。
- 良好的容错性,某个节点发生故障,HQL仍然可以正常完成。
- 统一的元数据管理,比如表,字段,类型
Hive 的缺点
- HQL 表达能力有限;
- 迭代计算无法表达;
- Hive的执行效率不高(基于MR的执行引擎);
- Hive自动生成的MapReduce作业,某些情况下不够智能;
- Hive的调优困难
Hive 架构
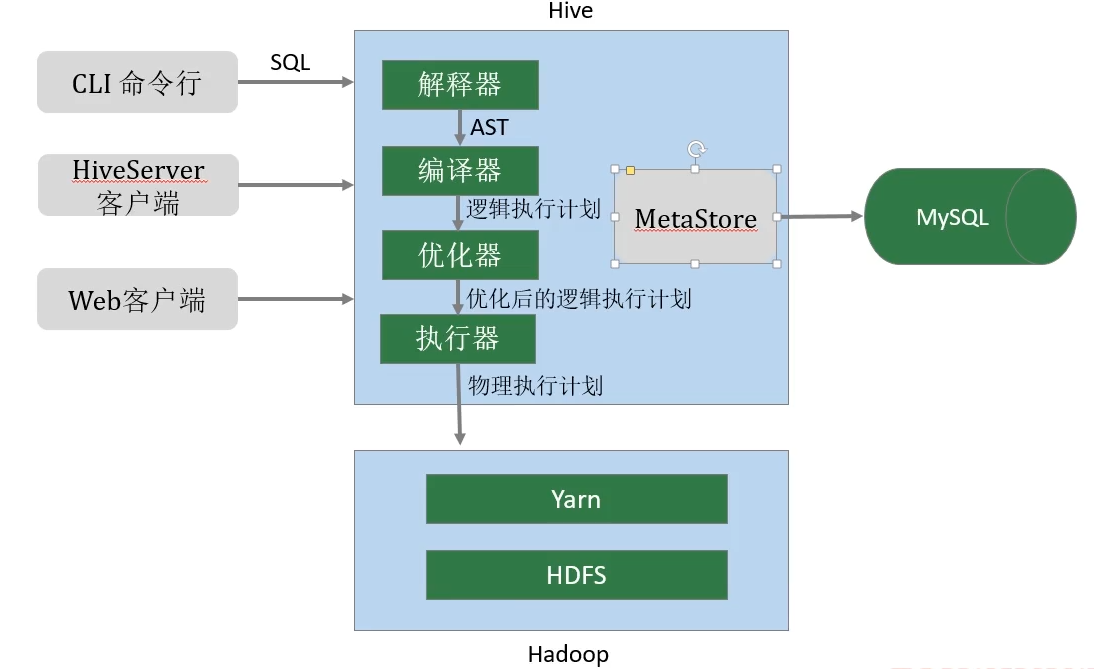
用户接口
- CLI(Common Line Interface):Hive的命令行,用于接收HQL,并返回结果;
- JDBC/ODBC:是指Hive的java实现,与传统数据库JDBC类似
- WebUI:是指可通过浏览器访问Hive
Thrift Server
- Hive可选组件,是一个软件框架服务,允许客户端使用包括Java,C++,Ruby和其他很多种语言,通过编程的方式远程访问Hive
元数据管理(MetaStore)
- Hive将元数据存储在关系数据库中(如mysql,derby),Hive的元数据包括:数据库名,表名及类型,字段名称及数据类型,数据所在位置等。
驱动程序(Driver)
- 解析器(SQLParser): 使用第三方工具(antlr) 将HQL字符串转换成抽象语法树(AST);对AST进行语法分析,比如字段是否存在,SQL语义是否有误,表是否存在;
- 编译器(Compiler): 将抽象语法树编译生成逻辑执行计划;
- 优化器(Optimizer): 对逻辑执行计划进行优化,减少不必要的列,使用分区等
- 执行器(Executr): 把逻辑执行计划转换成可以运行的物理计划