Hadoop 构成 HDFS + MapReduce + Yarn +Common
HDFS
Master/Slave
存入过程:
对于大数据进行拆分,切割得到数据库,可以得到多个数据块。
获取文件过程:
向NameNode请求获取到之前存入文件的块以及块所在的DataNode的信息,分别下载并最终合并,就得到之前的文件。
Master 节点:
管理和维护元数据,元数据记录了文件的块列表以及块所在的DataNode节点信息。
slave:
负责存储文件数据块
MN,DN:
既是角色名称,也是进程名称,也代指电脑节点
2NN:
辅助NameNode管理和维护元数据
Hadoop MapReduce:一个分布式的离线并行计算框架: 拆解任务,分散处理,汇整结果 MapReduce计算 = Map阶段 + Reduce阶段 Map阶段就是分的阶段,并行处理输入数据; Reduce阶段就是合的阶段,对Map阶段结果进行汇总;
分而治之
- 存储:拆分-》数据块
- 计算:拆分-》切分,切片
Map阶段目标:每个节点负责一个切片的计算。每个节点得到部分结果, Reduce阶段目标:合并阶段,就是把之前Map阶段输出,结果进行汇总得到全局的结果
Hadoop YARN :作业调度与集群资源管理框架
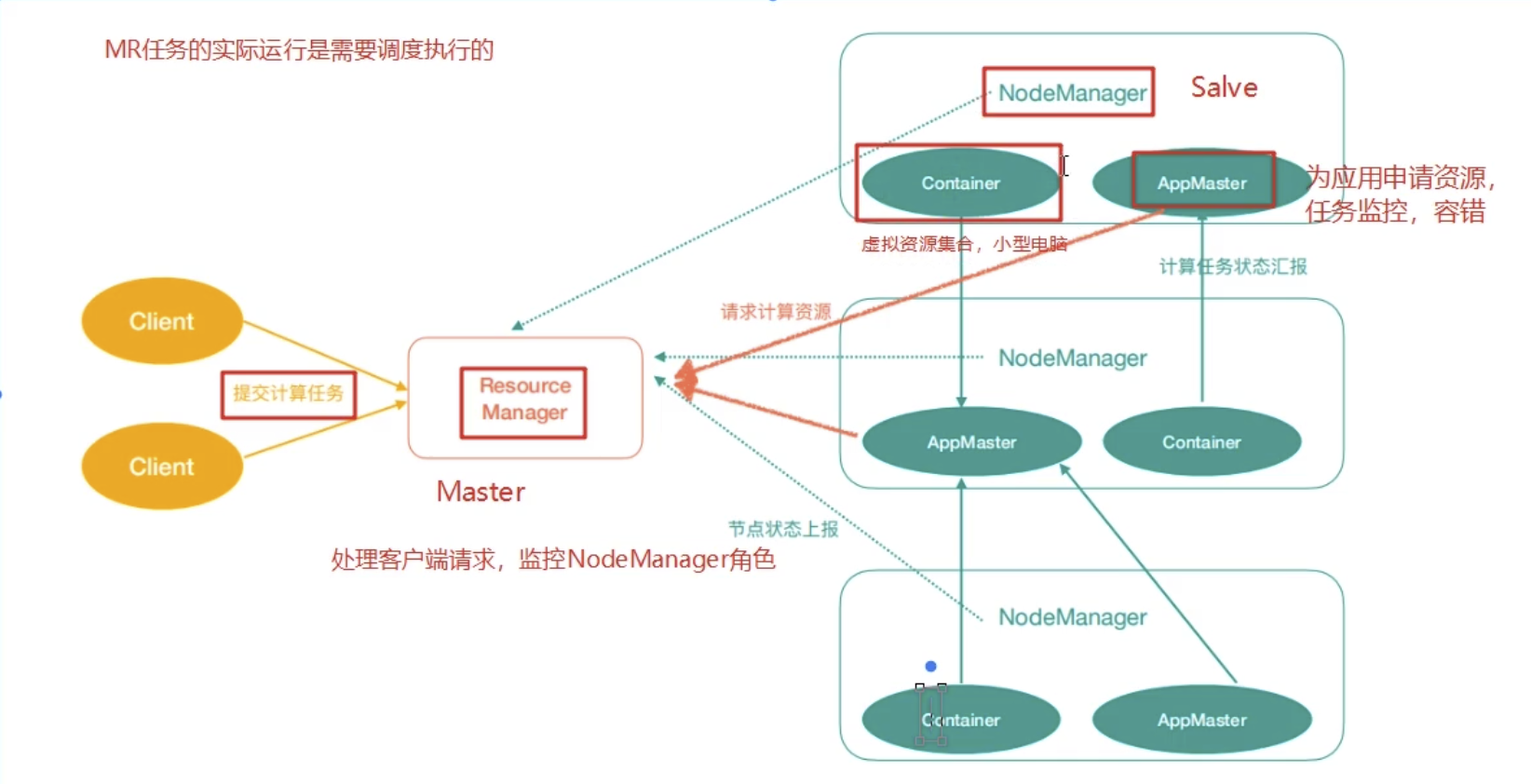
Yarn 中有几个角色,同样既是角色名,也是进程名,也指代所在计算机节点名称。
ResourceManager(rm):处理客户端请求,启动/监控ApplicationMaster,监控NodeManager,资源分配与调度。
NodeManger(nm):单个节点上的资源管理,处理来自ResourceManger的命令,处理来自ApplicationMaster的命令。
ApplicationMaster(am): 数据切分,为应用程序申请资源,并分配给内部任务,任务监控与容错。
Container: 对任务运行环境的抽象,封装了CPU,内存等多为资源以及环境变量,启动命令等任务运行相关的信息。
ResourceManager 是第一位,NodeManager是第二位,ApplicationMaster是计算任务专员。
Hadoop Common: 支持其他模块的工具模块(Configuation,RPC,序列化机制,日志操作)。
Hadoop 目录配置
- bin目录:对Hadoop进行操作的相关命令,如hadoop,hdfs等。
- etc目录:Hadoop的配置文件目录,如hdfs-site.xml,core-site.xml等。
- lib 目录:Hadoop本地库(解压缩的依赖)
- sbin目录:存放的Hadoop集群启动停止相关脚本,命令。
- share目录:Hadoop的一些jar,官方案例jar,文档等。
集群配置
Hadoop 集群配置 = HDFS 集群配置+MapReduce 集群配置+Yarn集群配置
- HDFS集群配置
- 将JDK路径明确配置给HDFS(修改hadoop-env.sh)
- 指定NameNode节点以及数据存储目录(修改core-site.xml)
- 指定SecondaryNameNode节点(修改hdfs-site.xml)
-
指定DataNode从节点(修改etc/hadoop/slaves文件,每个节点配置信息占一行)
-
MapReduce集群配置
- 将JDK路径明确配置给MapReduce(修改mapred-env.sh)
-
指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)
-
Yarn集群配置
- 将JDK路径明确给Yarn (修改yarn-env.sh)
- 指定ResourceManger老大节点所在计算机节点(修改yarn-site.xml)
- 指定NodeManager节点(会通过slaves文件内容确定)