java 基础
class 文件内容
class 文件包含java 程序执行的字节码,数据严格按照格式紧凑排列在class文件中的二进制流,中间无任何分隔符; 文件开头有一个0xcafebabe(16进制) 特殊的一个标志。
jvm 运行时数据区
.java源代码->.class 字节码->线程共享部分(方法区,堆内存)线程独占部分(虚拟机栈,本地方法栈,程序计数器) ->执行引擎->本地库接口->本地方法库
线程独占:
每个线程都会有它独立的空间,随线程生命周期而创建和销毁
线程共享:
所有线程能访问这块内存数据,随虚拟机或者GC而创建和销毁
方法区:
jvm 用来存储加载类信息,常量,静态变量,编译后的代码等数据 虚拟机规范中这是一个逻辑区划,具体实现根据不同虚拟机来实现 如:oracle 的hotspot 在java7中方法区放在永久层,java8放在元数据空间,并通过GC机制来对这个区域管理
堆内存:
细分为老年代,新生代(Eden,From Survivor,To Survivor) jvm 启动时创建,存放对象的实例,垃圾回收期主要就是管理堆内存。 如果满了,就会出现OutOfMemroyError,
虚拟机栈
每个线程都在这个空间有一个私有的空间,线程栈由多个栈帧组成,一个线程会执行一个或多个方法,一个方法对应一个栈帧 栈帧包含:局部变量表,操作数栈,动态链接,方法返回地址,附加信息等 栈内存默认最大是1M,超出则抛出StackOverflowError
本地方法栈
和虚拟机栈功能类似,虚拟机栈为虚拟机执行java方法准备的,本地方法栈是为了虚拟机使用native本地方法而准备的 虚拟机规范没有规定具体的视线,由不同的虚拟机厂商去实现 HotSpot虚拟机中虚拟机栈和本地方法栈的实现是一样的额,同样,超出大小以后也会抛出stackoverflowerror
程序计数器
程序计数器记录当前线程执行字节码的位置,存储是字节码的指令地址,如果执行native方法,则计数器值为空。 每个线程都在这个空间有一个私有的空间,占有内存空间很少。 cpu同一时间,只会执行一条线程中的指令。jvm多线程会轮流切换并分配cpu执行时间的方式,为了线程切换后,需要 通过程序计数器来恢复正确的执行位置 | 标志名称 | 标志值 | 含义 | | ------------ | ------------ | ------------ | | ACC_PUBLIC | 0x0001| public? | | ACC_FINAL | 0x0010 |final? 只有類 | | ACC_SUPER | 0x0020 | invokespecial ? | | ACC_INTERFACE | 0x0200 |接口 | | ACC_ABSTRACT | 0x400 |abstract ? | | ACC_SYNTHETIC |0x1000 | 非由用戶產生 | | ACC_ANNOTATION | 0x2000 |這是一個註解 | |ACC_ENUM|0x4000|這是一個枚舉| 類信息包含的静态常量,编译之后就能确认
class 内容
没有构造函数,会自动生成构造函数
main 方法
访问控制,本地变量数量,参数数量,方法对应栈中操作数的深度。jvm 执行这源码编译后的指令码 javap 翻译是操作符, class文件存储是指令码,前面是数字,是偏移量(字节) jvm根据这个区分不同的指令。
线程状态 java.lang.thread.state
- new 尚未启动的线程的线程状态
- running 可以运行线程的线程状态,等待cpu 调度
- blocked 线程阻塞等待监视器锁定的线程状态 处于synchronized 同步代码快或者方法被阻塞
- waiting 等待线程的线程状态,下列不带超时的方式:Object.wait,Thread.join,LockSupport.park
- TimedWaiting 具有等待时间的等待线程的线程状态: Thread.sleep,Object.wait,Thread.join,LockSupport.parkNanos,LockSupport.parkUntil
- Terminated:线程终止状态,线程正常完成执行或者出现异常
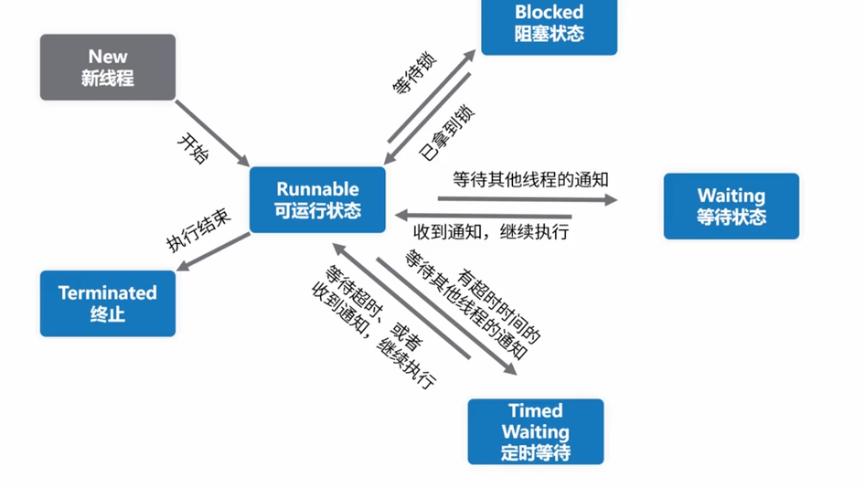
注意点:如果一个线程终止之后,再进行调用,会抛出IllegalThreadStateException 异常
线程终止
-
thread.interrupt 正确的线程终止 如果目标线程在调用Object class 的wait(),wait(long)或wait(long,int)方法,join(),join(long int)或者 sleep(long,int)方法时被阻塞,那么 interrupt会生效,该线程的终端状态被清除,抛出interruptedException异常。
如果目标线程是被I/O,或者NIO的channel 所阻塞,同样I/O操作会被中断或者返回特殊异常值,达到终止线程的目的。 如果以上条件都不满足,则会设置此线程的中断状态 2. 标志位 通过状态判断是否执行
cpu 缓存和内存屏障
l1 cache ,l2 cpu 外部高速储存器 ,l3 内置的,文件系统缓存。共享一个L3
缓存同步协议
多cpu读取同样的数据进行缓存,进行不同运算之后,使用MESI协议,规定每条缓存有个状态,同时定义了下面4个状态:
- 修改态(Modified)此cache行已被修改过(脏读) 内容不同于主存,为此cache专有。
- 专有态(exclusive) 此cache行内容同于主存,但不出现于其他cache中。
- 共享态(shared)此cache行内容同于主存,但也出现于其他cache中
- 无效态(invalid) 此cache行内容无效(空行)
多处理器时,单个cpu对缓存中数据进行了改动,需要通知给其他cpu,也就是说 CPU处理要控制自己的读写操作,还要监听其他cpu发出的通知,从而保证最终一致。
CPU 性能优化的手段,运行时指令重排
指令重排的场景,当cpu写缓存发现缓存区块正被其他cpu占用,为了提供cpu处理性能,可能会将后面的读缓存命 令优先执行。 当然要遵守as-if-serial 语意,不管怎么重排序单线程程序的执行结果不能被改变,编译器和处理器不会对存在数据 依赖关系的操作做重排序。
cpu 告诉缓存下有一个问题
缓存中数据和主内存的数据并不是实时同步,各个cpu 间缓存的数据也不是实时同步,在同一个时间点,各个cpu所看到 统一内存地址的数据的值可能是不一致的。
cpu 指令重排序
单仅在单cpu 自己执行的时候保证
内存屏障
写内存屏障(store barrier)能让写入缓存中的最新数据更新写入主内存,让其他线程可见,强制写入主内存,这种显示调用,cpu就不会因为性能考虑去对指令重排
读内存屏障(loadmemory barrier) 可以让告诉缓存中的数据失效,强制从新从主内存加载数据,强制读取主内存内容,让cpu 缓存与主内存保持一致,避免了缓存导致的一致性问题
通信的方式
要实现多个线程之间的协同,如:线程执行先后顺序,获取某个线程执行的结果等等,设计到线程之间相互通信,分为4种: 1.文件共享,2.网络共享,3.共享变量 4.jdk 提供的线程协调API :wait/notify,park/unpark
suspend 和resume
这两个容易产生死锁,改为 wait/notify
wait/notify
- 这些方法只能由同一对象锁的持有者线程电泳,也就是写在同步块里面,否则就会抛出illegalMonitorStateException 异常
- wait 方法导致当前线程等待,加入该对象的等待集合中,并且放弃当前持有的对象锁,notify/notifyAll 方法唤醒一个或所有正在等待这个对象锁的线程。
注意: 虽然wait 会自动解锁,但是对顺序有要求,如果在notify被调用之后,才开始wait方法的调用,线程将会永远处于waiting 状态。
park/unpark 机制
线程调用Park 则等待许可,unpark 方法为指定线程提供“许可(permit)" 不要求park 和unpark 方法的调用顺序 多次调用unpack之后,再调用park,线程会直接运行。 但不会叠加,连续多次调用park方法,第一次会拿到许可直接运行,后续调用会进入等待
伪唤醒
建议应该在循环中检查等待条件,原因是出于等待状态的线程可能会收到错误警报和伪唤醒,如果不在循环中检查等待条件,程序就会在没有满足条件的情况下退出。 伪唤醒指的是线程并非因为notify,notifyall,unpark等API调用而唤醒,是更底层原因导致的。
//wait
synchronized(obj){
while(<条件判断>)
obj.wait();
}
//park
while(<条件判断>)
LockSupport.park();
线程封闭概念
- 多线程访问共享可变数据时,涉及到线程间数据同步的问题,并不是所有时候,都要用到共享数据,所以线程封闭的概念提出来。
- 数据都被封闭在各自的线程之中,就不需要同步,这种通过将数据封闭在线程中而避免使用同步的技术成为线程封闭。
线程封闭具体的提现有:ThreadLocal,局部变量
ThreadLocal
ThreadLocal 是Java 里一种特殊的变量
它是一个线程级别变量,每个线程都有一个ThreadLocal就是每个线程都有了自己独立的一个变量,竞争条件被彻底消除了,在并发模式下是绝对安全的变量。
用法:ThreadLocal
栈封闭
局部变量的固有属性之一就是封闭在线程中,他们位于执行线程的栈中,其他线程无法访问这个栈。
为什么要用线程池
线程是不是越多越好?
- 线程在java中是一个对象,更是操作系统的资源,线程创建,销毁需要时间,如果创建和销毁的时间大于执行时间就不合算
- java 对象占有栈内存,操作系统线程占用系统内存,根据jvm 规范,一个线程默认最大栈大小1M。这个栈空间是需要从系统内存中分配的,线程过多,会消耗更多的内存。
- 操作系统需要频繁切换线程上下文,影响性能。 线程池的退出,就是为了方便的控制线程数量。
线程池原理
- 线程池管理器:用于创建并管理线程池,包括创建线程池,销毁线程池,添加新任务。
- 工作线程:线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
- 任务接口: 每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
- 任务队列: 用于存放没有处理的任务,提供一种缓冲机制。
线程池API 接口定义和实现类
- 接口,executor 最上层的接口,定义了执行任务的方法execute
- 接口, executorService 继承了executor,拓展了callable future 关闭方法
- 接口,scheduledExecutorService 基础标准的线程池实现
- 实现类,ThreadPoolExecutor 基础标准的线程池实现
- 实现类,ScheduledThreadPoolExecutor 继承了ThreadPoolExecutor,实现了ScheduledExecutorService 相关定时任务方法。
线程池API
检测executorService 是否已经关闭,直到所有任务完成执行,或超时发生,或当前线程被中断,awaitTermination(long timeout,timeUnit unit)
执行给定的任务集合,执行完毕后,返回结果, invokeAll(Collection<? extends Callable<T>> tasks)
执行给定的任务集合,执行完毕或超时后,返回结果,其他任务终止 invokeAll(Collection<? extends Callable<T>> tasks,long timeout,TimeUnit unit)
执行给定的任务,任意一个执行成功则返回结果,其他任务终止 invokeAny(Collection<? extends Callable<T>> tasks)
执行给定的任务,任意一个执行成功或者超时后,则返回结果,其他任务终止,invokeAny(Collection<? extends Callable<T>> tasks,long timeout,Timeunit unit)
如果此线程已关闭,则返回true isShutdown()
如果关闭后所有任务都已完成,则返回true ,isTerminated()
优雅关闭线程池,之前提交的任务将被执行,但是不会接受新的任务 shutdown()
尝试停止所有正在执行的任务,停止等待任务的处理,并返回等待执行任务的列表 shutdownNow()
提交一个用于执行的callable返回任务,并返回一个Future,用于获取Callable执行结果 submit(Callable<T>Task)
提交可运行任务以执行,并发回一个Future对象,执行结果为null,submit(Runnable task)
提交可运行任务以执行,并返回Future,执行结果为传入的result, submit(Runnable task,T result)
ScheduleExcutorService
schedule(Callable<V> callable,long delay,Timeunit unit) 和 schedule(Runable command,long delay,Timeunit unit) 创建并执行一个一次性任务,过了延迟时间就会被执行
scheduleAtFixedRate(Runnable command,long initialDelay,long period,Timeunit unit)
创建并执行了一个周期性任务
过来给定的初始延迟时间,会第一次被执行
执行过程汇总发生了一场,那么任务被停止
一次任务执行时长超过了周期时间,下一次任务会等到该次任务执行结束后,立刻执行,这也是它和scheduleWithFixedDelay的重要区别
scheduleWithFixedDelay(Runnable command,long initialDelay ,long delay,TimeUnit unit)
跟上面的区别是在上一次任务执行结束的时间基础上,再计算执行延时,上面超过周期就会立刻执行。